解决TCP延迟应答(Delay ACK)问题的3个方法
TCP延迟应答问题简单点说就是,如果条件(比较复杂,本文不论,自行google或者看看本文的附录)不符合,那么当发送一个数据段的时候,可能要等待40ms(对于Linux而言)到200ms(对于大多数Windows而言)的时间才会收到ACK。如果不巧,这段延迟叠加到总的传输时间中,对于这种情况该怎么解决呢?想了解延迟ACK带来的问题之具体场景的,请直接看附录。
接下来直接描述这个Trick本身。
正文
我们无法控制数据接收端的任何行为,事实上是否延迟应答并非全局参数控制的,而是TCP视连接内的瞬时情况而定的,这更加增加了解决问题的难度。
然而,TCP标准有一个规定,那就是收到乱序的数据报文时,会立即发送一个ACK,表现为DupACK或者DupSACK,这是考虑到立即的ACK(必然是重复的)会更加快速触发发送端的快速重传(收到n个重复ACK即快速重传)。这个规定就是可以利用的地方。
起初的想法比较铁公鸡,想一毛不拔地实现这个Trick,即发现是最后两段数据时,将两段数据颠倒发送,这就满足了上面的规定,然而修改代码的难度比较大,这是因为Linux的TCP实现耦合度太高了,代码并不优雅。于是想到用优雅换panic太不值,就想用空间换时间吧,反正总是要付出一些什么的。
以下的Trick点在于,如果发送一个“已经被ACK的数据段,将会触发接收端立即返回一个ACK”。以Linux的TCP栈实现为例,注意接收端的一个细节:
tcp_validate_incoming在收到发送端数据时调用,其中的一个细节是:
if (!tcp_sequence(tp, TCP_SKB_CB(skb)->seq, TCP_SKB_CB(skb)->end_seq)) {
if (!th->rst)
tcp_send_dupack(sk, skb);
goto discard;
}
这里的关键是,在收到的skb的seq满足一定条件的时候,会调用tcp_send_dupack,后者会立即发送一个ACK。我们来看看需要满足什么条件:
static inline int tcp_sequence(struct tcp_sock *tp, u32 seq, u32 end_seq)
{
return !before(end_seq, tp->rcv_wup) &&
!after(seq, tp->rcv_nxt + tcp_receive_window(tp));
}
只要保证这个数据段的end_seq在rcv_wup之前即可,那么rcv_wup是什么呢?它是万恶的TCP实现中保存的一个状态字段,表示“接收端上一次返回ACK的时候,其期望的rcv_nxt”!好吧,我们现在在发送端和接收端定义一个时间序列。接收端发送的ACK中携带的ACK号即其rcv_nxt,当该ACK到达发送端时会更新发送端的snd_una,在该时间序中,我们可以保证:
rcv_nxt >= snd_una
因此对于发送端而言,在某一时刻,我们可以认为:
rcv_wup == rcv_nxt >= snd_una
因此,发送端只需要在发送完最后一段数据后,在这段数据可能会触发接收端的延迟应答(Delay ACK)之前,顺便再发送一个0字节长度的构造好的数据段即可,另外,考虑到怕做无用功,等到实际有数据再次要发送时触发一个Trick段也行!幸运的是,不管以上哪个方案,与颠倒最后两段数据的发送不同,这个Trick实现起来非常简单!
Linux的TCP实现中,有一个现成的API可供调用:tcp_xmit_probe_skb
这是在发送0窗口探测以及keepalive探测时使用的。直接以参数0调用它即可,它的含义是,发送序列号为snd_una-1的长度为0的一个“废段”。代码添加的位置也是直观到极点:
Trick1:TCP发送队列发送到NULL时,发送Trick段
在tcp_write_xmit的while发送循环后面加一段:
if (skb == NULL) {
tcp_xmit_probe_skb(sk, 0);
}
Trick2:有新数据进入TCP发送队列时,判断是否为NULL,如果是,发送Trick段(场景详见附录2)
在skb_entail中的tcp_add_write_queue_tail前增加一段:
if (sk->sk_send_head == NULL) {
tcp_xmit_probe_skb(sk, 0);
}
两个修改可以全部启用,也可以启用一个,它们的区别在于,Trick1可能会更加激进,Trick2会更加恰当适应附录2所描述的场景。然后重新编译内核,接下来你就不会再看到延迟应答了!
如果对代码修改不感兴趣或者说根本就不熟悉,可以用packetdrill来验证以上的结论。这就是全部。但在以上这个Trick中,值得讨论的问题还是有的:
1.平白无故发送一个废数据段,这会带来流量开销
我认为这是无关紧要的,本来TCP就很难达到正好100%利用带宽资源,鉴于网络数据包的泊松特性,在从一个时间点开始极小时间段内,一个TCP连接对带宽资源的利用率要么大于100%,要么小于100%。并且除非发送到TCP发送队列的末尾,一般的诸如高性能WEB服务器都很难发生数据发送间断的情形(如果发生了,那就是WEB服务器的问题了,此时即便接收端快速回来个ACK也无卵用,因为真的没有数据可发送了,所以只有在延迟应答延迟期间,TCP发送队列里又有了数据,然而由于拥塞窗口原因未能发送的情形,这个Trick才会有效果)。
2.tcp_xmit_probe_skb并没有判断返回值,可能会发送失败
无所谓!本来这就是一个TCP“带外的”探测数据,成功了,带来收益,失败了,维持原状,不必为之付出成本。
3.tcp_xmit_probe_skb构造的skb没有缓存,会被网络默默丢弃
同上面的第2点。
4.能不能发送snd_nxt往后的序列号呢?或者说狠狠的往后,超越snd_nxt!
不能!因为首先你不能指望接收端会对这些数据段有任何反馈。其次,你还要面对数据覆盖的风险。比如你发了seq-seq+1(seq>snd_nxt)的数据,恰巧后面真正的seq-seq+1的数据在网络上丢了,那么这就是一次成功的前向注入!不过协议栈还是勇于避免这种情况的发生了。
最后值得一提的是,nmap正是用这种细节性的行为来探测协议栈,然后根据其反应来获得内部细节。由于不同的系统对规范的理解会稍有不同,这种不同最终会反映在数据和行为上。比如Windows和Linux计算TCP初始序列号的算法就不同,如果搜集这些序列号,就会发送一系列的模式,这就是指纹。再比如,对于RFC上没有明确规定为MUST的那部分,各个系统就会有自己的解释,不同的解释造就了不同的行为,这些也是指纹。nmap几乎可以让你构造所有的可以在网络上发送的数据包进行网络的探测,如果你想对网络有一个全面且深入的理解,请直接从nmap+scapy开始(together with ping,traceroute,telnet)。
正文完!正文仅仅描述了怎么去修改,至于很多的为什么,都在附录里。
附录1:延迟应答的触发条件
下面的代码描述了,在什么条件下会立即发送一个ACK,然后我们也就知道了什么条件下会有一个延迟的应答:
/* More than one full frame received… */
if (((tp->rcv_nxt – tp->rcv_wup) > inet_csk(sk)->icsk_ack.rcv_mss
/* … and right edge of window advances far enough.
* (tcp_recvmsg() will send ACK otherwise). Or…
*/
&& __tcp_select_window(sk) >= tp->rcv_wnd) ||
/* We ACK each frame or… */
tcp_in_quickack_mode(sk) ||
/* We have out of order data. */
(ofo_possible && skb_peek(&tp->out_of_order_queue))) {
/* Then ack it now */
tcp_send_ack(sk);
}
1.本地接收但未ACK的数据量大于一个rcv_mss
这个主要由(tp->rcv_nxt – tp->rcv_wup) > inet_csk(sk)->icsk_ack.rcv_mss来保证。rcv_nxt为当前的rcv_nxt,而rcv_wup为上一次发送ACK时的rcv_wup,二者的差就是收到的连续的但是未被确认的数据量,它如果大于rcv_mss,则立即发送一个ACK。
我们来用packetdrill模拟一下满足条件或者不满足条件的场景,以下是一个脚本:
0.000 socket(…, SOCK_STREAM, IPPROTO_TCP) = 3
0.000 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
0.000 bind(3, …, …) = 0
0.000 listen(3, 1) = 0
0.000…0.200 accept(3, …, …) = 4
0.100 < S 0:0(0) win 32792 <mss 1460, sackOK, nop, nop, nop, wscale 7>
0.100 > S. 0:0(0) ack 1 <…>
0.200 < . 1:1(0) ack 1 win 100
0.300 < P. 1:1001(1000) ack 1 win 16425
0.300 < P. 1001:2001(1000) ack 1 win 16425
// 发送数据,携带ACK过去
0.300 write(4, …, 1000) = 1000
// 打印rcv_mss的值,指导下面发送的数据构造
0.300 %{ print tcpi_rcv_mss }%
0.300 < P. 2001:2701(700) ack 1001 win 16421
//0.300 < P. 2701:xxx?(yyy?) ack 1001 win 16421
// 延迟,无意义!
10.300 write(4, …, 13) = 13
上例中的xxx和yyy最大应该是多少呢?看上面的那个条件,我们必须知道rcv_mss后才能算xxx是多少!跑一遍这个脚本后,打印出rcv_mss结果是1000,那么要想触发延迟应答,算式tp->rcv_nxt – tp->rcv_wup的值最大就是1000,因此把yyy设置为1000-700=300,把xxx设置成3001,测试一遍,果然触发了延迟应答:
01:32:55.683903 IP 192.168.0.1.webcache > 192.0.2.1.51358: Flags [.], ack 2001, win 92, length 0
01:32:55.683921 IP 192.0.2.1.51358 > 192.168.0.1.webcache: Flags [P.], seq 2001:2701, ack 3530906528, win 16421, length 700
01:32:55.683931 IP 192.0.2.1.51358 > 192.168.0.1.webcache: Flags [P.], seq 2701:3001, ack 3530906528, win 16421, length 300
01:32:55.723801 IP 192.168.0.1.webcache > 192.0.2.1.51358: Flags [.], ack 3001, win 123, length 0
为了验证最大是300,我们把yyy改成301试一下,结果是:
01:40:55.122897 IP 192.168.0.1.webcache > 192.0.2.1.53528: Flags [.], ack 2001, win 92, length 0
01:40:55.122918 IP 192.0.2.1.53528 > 192.168.0.1.webcache: Flags [P.], seq 2001:2701, ack 817105298, win 16421, length 700
01:40:55.122930 IP 192.0.2.1.53528 > 192.168.0.1.webcache: Flags [P.], seq 2701:3002, ack 817105298, win 16421, length 301
01:40:55.122934 IP 192.168.0.1.webcache > 192.0.2.1.53528: Flags [.], ack 3002, win 123, length 0
接收端立即就发送了应答,而没有延迟!
根据以上的不等式,我们再来确认一个问题。
如果你查关于延迟应答的资料,很多人会说“最多在收到2个数据段”,这句话未免太过笼统和抽象,我们来看下细节是什么。假设上述的tcpi_rcv_mss=1000成立,我们再次构造这个packetdrill脚本:
0.000 socket(…, SOCK_STREAM, IPPROTO_TCP) = 3
0.000 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
0.000 bind(3, …, …) = 0
0.000 listen(3, 1) = 0
0.000…0.200 accept(3, …, …) = 4
0.100 < S 0:0(0) win 32792 <mss 1460, sackOK, nop, nop, nop, wscale 7>
0.100 > S. 0:0(0) ack 1 <…>
0.200 < . 1:1(0) ack 1 win 100
0.300 < P. 1:1001(1000) ack 1 win 16425
0.300 < P. 1001:2001(1000) ack 1 win 16425
0.300 write(4, …, 1000) = 1000
0.300 %{ print tcpi_rcv_mss }%
0.300 < P. 2001:2701(700) ack 1001 win 16421
0.300 < P. 2701:2731(30) ack 1001 win 16421
0.300 < P. 2731:2751(20) ack 1001 win 16421
0.300 < P. 2751:2851(100) ack 1001 win 16421
10.300 write(4, …, 13) = 13
这下一次性发走4个数据段,跑一遍看看结果:
02:25:55.754432 IP 192.168.0.1.webcache > 192.0.2.1.49244: Flags [.], ack 2001, win 92, length 0
02:25:55.754446 IP 192.0.2.1.49244 > 192.168.0.1.webcache: Flags [P.], seq 2001:2701, ack 216776498, win 16421, length 700
02:25:55.754454 IP 192.0.2.1.49244 > 192.168.0.1.webcache: Flags [P.], seq 2701:2731, ack 216776498, win 16421, length 30
02:25:55.754457 IP 192.0.2.1.49244 > 192.168.0.1.webcache: Flags [P.], seq 2731:2751, ack 216776498, win 16421, length 20
02:25:55.754461 IP 192.0.2.1.49244 > 192.168.0.1.webcache: Flags [P.], seq 2751:2851, ack 216776498, win 16421, length 100
02:25:55.794319 IP 192.168.0.1.webcache > 192.0.2.1.49244: Flags [.], ack 2851, win 107, length 0
依然触发了40ms的延迟应答。同样的,即使你发送5个段,只要其总大小不超过rcv_mss,也依然会延迟应答,所以说与其说背诵那种应对延迟ACK的奇数偶数拆包封包的口诀,还不如记住上面的这个不等式。当然,我这里说的只是对于Linux(2.6.32版内核)的实现而言,对于Windows,并不能保证一定就是这样。
因此,话应该这么说:只要收到未确认的数据量小于等于rcv_mss,就会延迟应答,无论多少个数据段,请自行忘掉奇数偶数这种场景分类法“。验证本文描述的Trick的时候到了:
packetdrill脚本中在发送完数据后,添加一行:
0.300 < P. 2001:2701(700) ack 1001 win 16421
0.300 < P. 2701:2731(30) ack 1001 win 16421
0.300 < P. 2731:2751(20) ack 1001 win 16421
0.300 < P. 2751:2851(100) ack 1001 win 16421
0.300 < P. 1:1(0) ack 1001 win 16421
此时再次运行,结果是:
02:29:43.518237 IP 192.168.0.1.webcache > 192.0.2.1.60025: Flags [.], ack 2001, win 92, length 0
02:29:43.518256 IP 192.0.2.1.60025 > 192.168.0.1.webcache: Flags [P.], seq 2001:2701, ack 3801173596, win 16421, length 700
02:29:43.518265 IP 192.0.2.1.60025 > 192.168.0.1.webcache: Flags [P.], seq 2701:2731, ack 3801173596, win 16421, length 30
02:29:43.518271 IP 192.0.2.1.60025 > 192.168.0.1.webcache: Flags [P.], seq 2731:2751, ack 3801173596, win 16421, length 20
02:29:43.518276 IP 192.0.2.1.60025 > 192.168.0.1.webcache: Flags [P.], seq 2751:2851, ack 3801173596, win 16421, length 100
02:29:43.518280 IP 192.0.2.1.60025 > 192.168.0.1.webcache: Flags [P.], ack 3801173596, win 16421, length 0
02:29:43.518283 IP 192.168.0.1.webcache > 192.0.2.1.60025: Flags [.], ack 2851, win 107, length 0
立即发送了应答,没有延迟!最后的问题是,为什么发送序列号为1呢?事实上只要是snd_una-1即可,或者说小于snd_una-1的都可以,只要满足before(end_seq, tp->rcv_wup)即可,具体详见正文。之所以取snd_una是因为这是一个可以预期的值,取值有理有据,且不会引发其它的valid逻辑。
2.quick mode…(不讨论)
3.乱序队列中有数据(不讨论)
附录2:延迟应答导致危害的场景
延迟应答本身没有任何危害,否则就不会有这个机制了。它只是与Nagle算法以及拥塞窗口结合的时候才会导致问题,其实”Nagle算法+延迟应答“以及”拥塞控制+延迟应答“说的是同一类问题,都是”自私地误解对方导致的同时等待“引起,它们分别在等待什么呢?我用下面的图来解释这个问题:
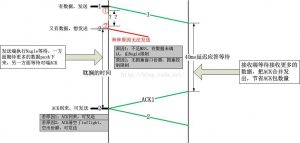
因此,不管发生哪种情况,消解对端的延迟应答是根本解决之道。这就是正文中所描述的两个Trick(详见Trick1和Trick2)的应用场景。
Trick2要比Trick1更加理性一些,它们的区别在于是在上图中红圈1还是红圈2的时刻发送Trick包!两种情况:
1).如果在1时刻发送的话,如果后面再也没有数据发送,那么就会浪费一个Trick包,不过前面我也说过,这无关紧要,然而对于强迫症者来讲这不可接受,不得不以一个RTT的代价选择Trick2;
2).如Trick2所示,在2时刻发送的话,不会浪费Trick包,该Trick包百分百用于触发对端赶紧回ACK,如1和2之间的间隔是两个问号,问号到底是多少呢?答案是大于一个RTT(大于一个RTT时间,ACK都没有来,
大概率说明对端启用了延迟应答,然而并不排除ACK丢失!)。如果在2时刻发送Trick包,将会在一个RTT后收到ACK1,进而触发数据2的发送,相比Trick1,这会浪费掉一个RTT,然而对于RTT在40ms内的连接来讲,这就是收益的来源!
接下来,我来说一下在延迟应答导致危害的场景中的两个经典例子,即”Write-Write-Read模式“和”最后一段不足MSS“。事实上,这两个经典例子也是可以合并为一类的,二者并没有明确的界限。
Write-Write-Read问题:
在Write-Write-Read模式中,受到延迟应答的影响是最大的,网上很多文章都提到了Write-Write-Read,但是并没有说其细节。我试图表白一下,这种模式更多的是形容一种应用层协议的模式,比如HTTP协议:
Client->Server:Get
Server->Client:Response —1(Write to Clinet)
Server->Client:Body —2(Write to Client)
Client->Server:Next… —3(Read from Client)
上述的1,2,3就构成了一个典型的Write-Write-Read,如果说步骤1中Write的数据不足一个MSS,那么就会触发Client的延迟应答,此时的步骤2就会延迟40ms执行(对于Linux而言),如果在步骤1之后,发送一个Trick段,将解决这个问题。
至于说为什么Write-Read-Write-Read-Write-Read-Write…不会有问题,请自行脑补”捎带ACK“,如果连这都不懂,请辞职!
Trick终究是Trick,只为炫技巧,显得自己对代码比较熟,没有别的卵意义,本质的解决方案在应用程序的设计,还是以HTTP为例,在Response和Body连续发送时,如果Response小于一个MSS,请与后面的Body拼接成一个MSS的buffer一起发送!
对于拥塞控制导致的数据无法发送,要想继续发送数据,只要保证当前的拥塞窗口与inflight的差值不为0即可,那么势必要引导ACK来清空inflight数据,这样一来Trick包十分有效,如果考虑到ACK丢失的情况,就更加复杂了,不管怎样,记住一点:让最小的拥塞窗口大于1个MSS,最少2个MSS(因为接收端即便延迟应答,也最多缓存2个MSS的数据)!当前的Linux实现中,发生重传定时器超时事件后,拥塞窗口将会设置成1,然后恢复后可能就从1开始慢启动,这个大小为1的拥塞窗口只允许初始发送1个段,因此会触发对端的延迟应答,此时发送一个Trick包可以解决问题,然而根本的解决之道是,在超时重传恢复到正常状态后,拥塞窗口最小从2开始慢启动。修改下面的代码:
将tcp_undo_cwnd_reduction中的下面一段:
tp->snd_cwnd = max(tp->snd_cwnd, tp->snd_ssthresh << 1);
修改为:
tp->snd_cwnd = max_t(max(tp->snd_cwnd, tp->snd_ssthresh << 1), 2U);
最后一段不足MSS的问题:
我认为这根本不是问题!
这涉及到两边谁先close。如果是发送端先close,那么一个FIN数据段将会pending到发送队列,在窗口允许发送的情况下(几乎都是允许的!),FIN会立即发送出去,这个FIN会带来接收端的立即应答!因此如果服务端认为自己发完了数据,close掉了连接,那么其后续的FIN将会消解延迟应答。
如果是接收端收到了自己预期的数据,调用了close,那该close会发送一个FIN,该FIN是立即发送的,捎带本应该延迟的ACK到达发送端。
所以说,如果说是简单的下载模式,即Write-Write-Write-Write-Write-Write-Write…模式,那么这两个Trick几乎没有用武之地,说”几乎“而不是”一定“,那是因为无论怎样,我们一定要考虑拥塞窗口的限制,拥塞窗口只限制大小而并不滑动,所以说如果拥塞窗口限制住不能再发送数据了,那么此时来一个ACK将会取消这个限制!
只要任何一端调用了close,那么这个”最后一段不足MSS“导致的延迟应答问题就马上会转化为”Write-Read-Write“问题而消解,close会触发4次挥手逻辑,而这个逻辑是无延迟强交互的。如果两端谁都不close,那说明两端根本不在乎时间,延迟就让它去延迟吧!
本附录综上,延迟应答在单向数据传输中,没有半点危害,延迟应答本身就是为提高单向数据传输的吞吐量而设计的,然而对于交互场景,延迟应答会影响响应度,正如效率和公平之间的关系一样,吞吐量和响应度之间也是互斥的关系,明白了点什么吗?TCP是一个传输层协议,并不理解应用层的语义,因此TCP并不知道应用层是”单向传输“还是”交互“,正如HTTP的例子一样,在下载一个大文件(典型的单向传输场景)之前,浏览器会和WEB服务器交互几组数据(典型的交互场景),请问TCP知道这些吗?如果知道,它当然就会知道什么时候要延迟应答而什么时候不要,不幸的是,TCP并不知道,这又是一个TCP又瞎又傻的案例!跟蝙蝠或者拉二胡的阿炳一样,TCP是个大瞎子,和蝙蝠或者拉二胡的阿炳不同的是,TCP还是个二傻子。TCP的特性总是需要找平衡点的,往往一个特性增益了这个却污损了那个,永远不要试图以一句很绝对的话来评判TCP的某个特性。
本附录本不该有,这无关技术,是关于形而上的东西,因此,我以嘲讽的语调来结束本附录!
我其实十分讨厌这种将问题分解为模式的方法,明明就是一个问题,非要分离出不同的场景,搞得根本很难理解问题的本质。当然对于经受了超过N年正规教育的人而言,这种”口诀法“对于大脑填鸭是十分有益的,人们早就已经习惯了这种方式,毕竟从中学甚至小学时起,我们就已经开始做这种训练了,把一篇课文基于自然段分大段,然后归纳为”总-分-总“,”总-分“,”分-总“…几类中某一类,并总结段落大意,归纳出中心思想…有人会反驳说好多这种模式都是老外总结出来的,我倒是想说这是你歪曲了柏拉图以及笛卡尔的本意,或者说更激进一点,21世纪早就已经过了那种”理想化分类“的时代,因为人们已经意识到,大多数东西,拆了就组装不起来了。所以说,正交基是不存在的!
每每遇到这种分类,我就默默地将其融合,然后试图弥补它们从前的裂痕,每每身处那种关于此话题的争论的场合,我只能选择闭嘴或者离开!
附录3:第3个Trick
题目中说的3个Trick,正文中只有2个,那么第3个呢?
第3个Trick是一个现成的逻辑,已经在Linux协议栈中实现。关于Nagle算法的一个细节,它只在TCP发送队列的最后一个skb被发送时才有效,且看以下代码:
if (unlikely(!tcp_nagle_test(tp, skb, mss_now,
(tcp_skb_is_last(sk, skb) ?
nonagle : TCP_NAGLE_PUSH))))
break;
只有在这是TCP发送队列的最后一个skb时,才会应用Nagle算法逻辑,否则一律无条件PUSH,这个简单的实现,可读性非常好且效率很高,代码并没有针对每一个skb都去执行一下Nagle算法,而是整合成一个串行流水的操作!