BBR中的即时带宽计算
即时带宽的计算
bbr作为一个纯粹的拥塞控制算法,完全忽略了系统层面的TCP状态,计算带宽时它仅仅需要两个值就够了:
1).应答了多少数据,记为delivered;
2).应答1)中的delivered这么多数据所用的时间,记为interval_us。
将上述二者相除,就能得到带宽:
bw = delivered/interval_us
非常简单!以上的计算完全是标量计算,只关注数据的大小,不关注数据的含义,比如delivered的采集中,bbr根本不管某一个应答是重传后的ACK确认的,正常ACK确认的,还是说SACK确认的。bbr只关心被应答了多少!
这和TCP/IP网络模型是一致的,因为在中间链路上,路由器交换机们也不会去管这些数据包是重传的还是乱序的,然而拥塞也是在这些地方发生的,既然拥塞点都不关心数据的意义,TCP为什么要关注呢?反过来,我们看一下拥塞发生的原因,即数据量超过了路由器的带宽限制,利用这一点,只需要精心地控制发送的数据量就好了,完全不用管什么乱序,重传之类的。当然我的意思是说,拥塞控制算法中不用管这些,但这并不意味着它们是被放弃的,其它的机制会关注的,比如SACK机制,RACK机制,RTO机制等。
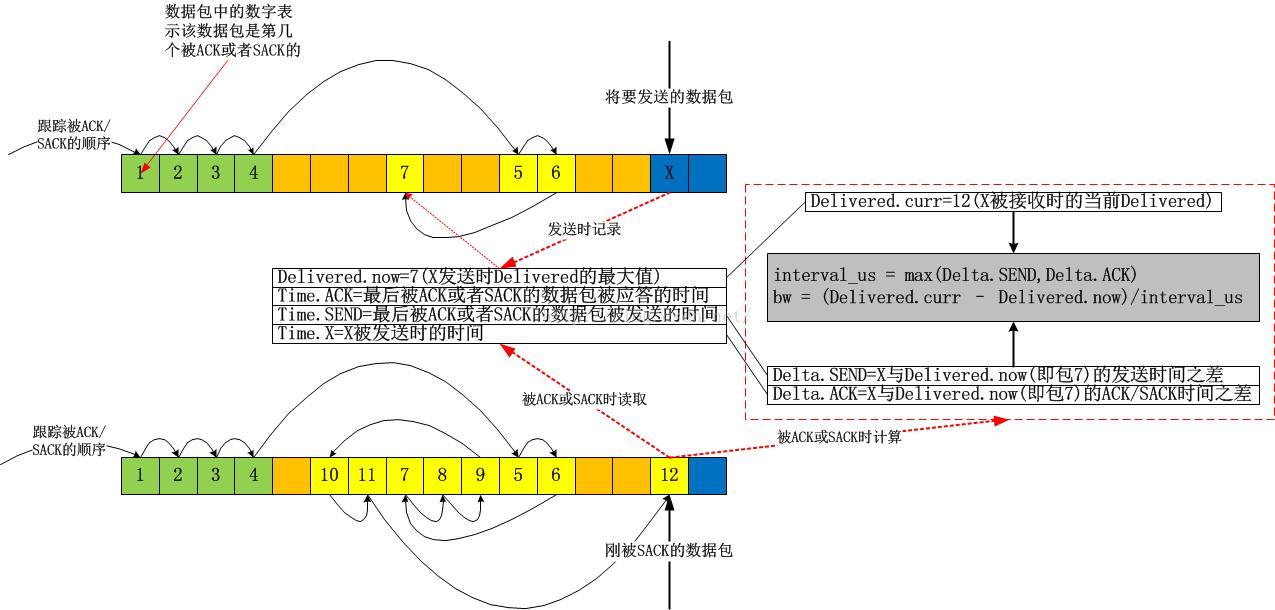
接下来我们看一下这个delivered以及interval_us的采集是如何实现的。还是像往常一样,我不准备分析源码,因为如果分析源码的话,往往难以抓住重点,过一段时间自己也看不懂了,相反,画图的话,就可以过滤掉很多诸如unlikely等异常流或者当前无需关注的东西:
上图中,我故意用了一个极端点的例子,在该例子中,我几乎都是使用的SACK,当X被SACK时,我们可以根据图示很容易算出从Delivered为7时的数据包被确认到X被确认为止,一共有12-7=5个数据包被确认,即这段时间网络上清空了5个数据包!我们便很容易算出带宽值了。我的这个图示在解释带宽计算方法之外,还有一个目的,即说明bbr在计算带宽时是不关注数据包是否按序确认的,它只关注数量,即数据包被网络清空的数量。实实在在的计算,不猜Lost,不猜乱序,这些东西,你再怎么猜也猜不准!
计算所得的bw就是bbr此后一切计算的基准。