字节缓存(一)
目前学术上的切分方法如下:
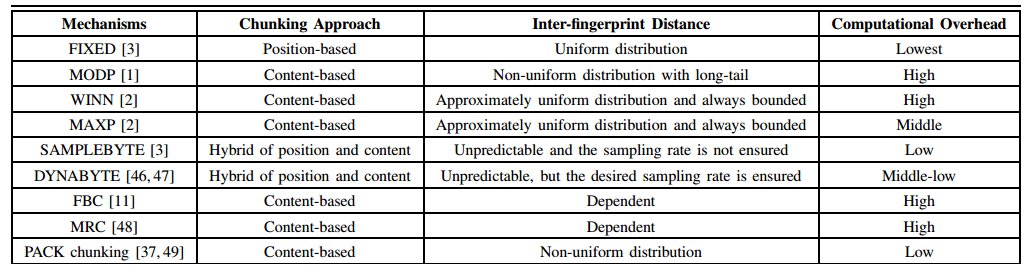
上图中的9种方法可以根据方法自身的特性分为三类。
第一类:位置分类法,此方法按固定大小将数据切分。其方法的优势的计算开销很小,但是对数据变化很敏感。
第二类:取样法,MODP、WINN、MAXP、SAMPLEBYTE、DYNABYTE均属于此类。由于计算指纹的时候是按字节递增取块计算,因此
指纹的数量会很多,考虑到内存和磁盘的压力,取样法根据全局条件、局部条件、统计结果来取样数据块。
第三类:全局缓存,MRC和PACK属于此类,此类方法按照一定的方法将数据块切分,再对切分后的数据块计算hash值并存储。
剩下的FBC方法[6]的创新点是评估出使用频率高的块,以此来节省内存与磁盘的开销。
1.FIXED
按固定大小划分数据的最大问题对数据修改十分敏感,一旦某一个位置的数据修改后,其后所有数据的hash值均发生了变化。
2.MODP
此方法由论文[1]于2000年提出。其系统架构如下:
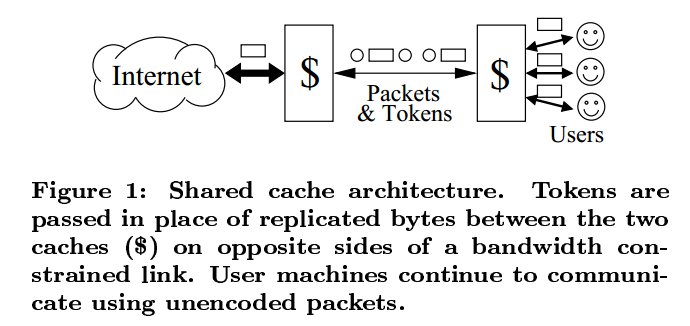
MODP的实现:
MODP是通过指纹来找到重复的数据。
- 指纹通过Rabin指纹算法计算。
- 对数据包计算了所有指纹之后,由于数据量巨大,我们需要取样。取样对指纹二进制表示时最后几位为0的指纹。
- 采用hash表来存放指纹,对相同的指纹采用FIFO的方式处理。如果查询到相同的指纹,向两边扩散比较。
MODP的伪代码如下:

效果分析:
可以通过伪代码中的参数p来控制取样的数目,如果取样的数目很少的话,就会效果很差,因为大量的数据没有取样。
如果取样很多的话,那么就会让MODP接近于FIXED方法。而且我们以全局的参数p来定义划分的条件,因此有可能很多
区域并没有取样。
3.WINN
此方法由论文[2]提出, 此方法可以保证在一定范围的hash值中一定会取一个局部最小或局部最大的hash值。此方法的优势
在于可以让取样均匀分布,可用于解决MODP中的大范围取样失效。
4.MAXP
在MODP和WINN中,我们计算了大量的指纹,但是很多指纹并没有被取样。MAX会选择局部数据内容的最大值而不是WINN的
局部指纹的最大值,MAX选择出最大值后在计算指纹。此方法由论文[3]提出。
5.SAMPLEBYTE
此方法的伪代码如下:

对于此方法[4]使用取样的字节来设置切割点,由上图可知,取样的自己存放于SMPLETABLE数组。
在第6行,一旦确认需要取样,就设置取样点并将i滑动p/2字节。 在离线方式下,数组SMPLETABLE是
通过对MAXP的结果进行排序得到。在实验中验证,其方法效果并没有很大改善,原因可能是:取样出来
字节和重复的部分并不一定有联系。
6.DYNABYTE
由于SAMPLEBYTE存在SMPLETABLE数组大小是固定和需要预先对数据进行训练这两个问题,论文[5]提出了
DYNABYTE方法,此方法类似于SAMPLEBYTE,但是可以自适应的动态对查询表进行调整。